

Is our machine mastering? Ars will take a dip into synthetic intelligence

Every day, some small piece of logic manufactured by really precise bits of synthetic intelligence technological know-how would make decisions that have an effect on how you encounter the earth. It could be the advertisements that get served up to you on social media or searching internet sites, or the facial recognition that unlocks your phone, or the directions you get to get to wherever you’re going. These discreet, unseen selections are becoming designed mainly by algorithms developed by device discovering (ML), a segment of artificial intelligence technologies that is properly trained to recognize correlation involving sets of data and their outcomes. We’ve been hearing in movies and Television for years that pcs management the globe, but we have lastly achieved the place the place the machines are generating real autonomous choices about stuff. Welcome to the upcoming, I guess.
In my days as a staffer at Ars, I wrote no modest quantity about synthetic intelligence and machine studying. I talked with info scientists who were being constructing predictive analytic units dependent on terabytes of telemetry from complicated methods, and I babbled with developers attempting to establish methods that can protect networks in opposition to attacks—or, in selected situations, actually stage all those attacks. I have also poked at the edges of the engineering myself, using code and hardware to plug several issues into AI programming interfaces (at times with horror-inducing effects, as demonstrated by Bearlexa).
Quite a few of the complications to which ML can be applied are tasks whose situations are evident to human beings. That is due to the fact we are trained to recognize individuals issues by observation—which cat is much more floofy or at what time of day traffic will get the most congested. Other ML-correct problems could be solved by individuals as well presented adequate uncooked data—if humans experienced a perfect memory, best eyesight, and an innate grasp of statistical modeling, that is.
But machines can do these jobs substantially speedier mainly because they will not have human constraints. And ML permits them to do these duties devoid of human beings owning to software out the certain math concerned. As an alternative, an ML procedure can learn (or at the very least “master”) from the data supplied to it, creating a problem-resolving product by itself.
This bootstrappy strength can also be a weakness, nevertheless. Knowledge how the ML technique arrived at its decision approach is usually not possible after the ML algorithm is created (inspite of ongoing do the job to build explainable ML). And the quality of the success relies upon a wonderful offer on the high-quality and the amount of the details. ML can only answer inquiries that are discernible from the info alone. Lousy facts or insufficient data yields inaccurate models and lousy machine understanding.
Irrespective of my prior adventures, I have never carried out any real building of machine-discovering methods. I’m a jack of all tech trades, and whilst I am superior on basic details analytics and functioning all kinds of databases queries, I do not contemplate myself a info scientist or an ML programmer. My previous Python adventures are a lot more about hacking interfaces than creating them. And most of my coding and analytics techniques have, of late, been turned towards exploiting ML applications for quite certain needs similar to details protection study.
My only actual superpower is not staying scared to consider and fall short. And with that, audience, I am right here to flex that superpower.
The undertaking at hand
Right here is a activity that some Ars writers are extremely superior at: composing a reliable headline. (Beth Mole, you should report to acquire your award.)
And headline creating is hard! It truly is a task with lots of constraints—length remaining the largest (Ars headlines are minimal to 70 people), but nowhere near the only 1. It is a problem to cram into a little space sufficient information to properly and adequately tease a tale, although also like all the points you have to set into a headline (the conventional “who, what, in which, when, why, and how several” collection of facts). Some of the things are dynamic—a “who” or a “what” with a notably long title that eats up the character count can actually throw a wrench into factors.
As well as, we know from expertise that Ars viewers do not like clickbait and will fill up the feedback segment with derision when they think they see it. We also know that there are some things that persons will click on with out fail. And we also know that irrespective of the subject, some headlines final result in much more persons clicking on them than other individuals. (Is this clickbait? You will find a philosophical argument there, but the major factor that separates “a headline everybody wants to simply click on” from “clickbait” is the headline’s honesty—does the tale beneath the headline completely produce on the headline’s assure?)
Irrespective, we know that some headlines are extra helpful than other folks mainly because we do A/B tests of headlines. Each individual Ars posting commences with two probable headlines assigned to it, and then the internet site provides both equally solutions on the household web page for a brief period to see which a single pulls in additional traffic.
There have been a couple scientific studies accomplished by details researchers with substantially far more experience in facts modeling and device learning that have appeared into what distinguishes “clickbait” headlines (kinds made strictly for having substantial numbers of people today to click on by to an report) from “fantastic” headlines (types that really summarize the article content powering them successfully and will not make you produce lengthy grievances about the headlines on Twitter or in the responses). But these studies have been centered on knowledge the content material of the headlines somewhat than how lots of true clicks they get.
To get a photograph of what readers seem to like in a headline—and to test to comprehend how to create improved headlines for the Ars audience—I grabbed a established of 500 of the most quickly clicked Ars headlines from the previous 5 several years and did some organic language processing on them. Right after stripping out the “cease phrases”—the most generally taking place text in the English language that are typically not related with the theme of the headline—I created a term cloud to see what themes generate the most awareness.
Below it is: the form of Ars headlines.
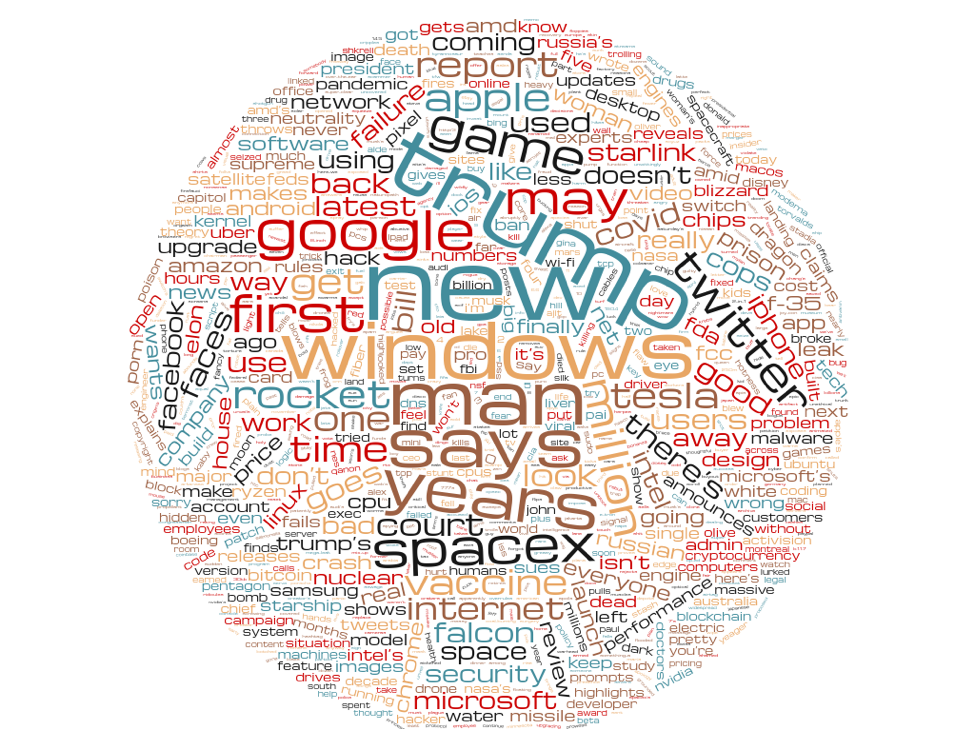
There is a entire large amount of Trump in there—the previous handful of several years have included a good deal of tech news involving the administration, so it can be almost certainly unavoidable. But these are just the terms from some of the profitable headlines. I required to get a sense of what the difference involving profitable and getting rid of headlines were. So I yet again took the corpus of all Ars headline pairs and break up them between winners and losers. These are the winners:

And in this article are the losers:
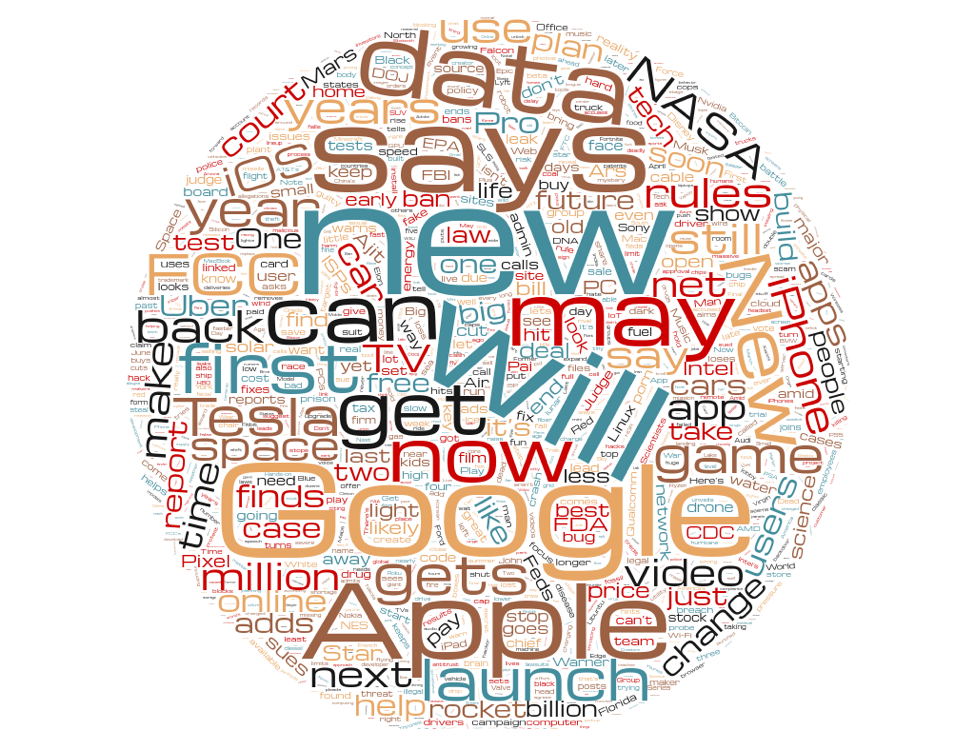
Don’t forget that these headlines were written for the precise identical stories as the profitable headlines ended up. And for the most aspect, they use the exact same words—with some noteworthy distinctions. There is certainly a total large amount less “Trump” in the shedding headlines. “Million” is seriously favored in winning headlines, but to some degree much less so in losing types. And the phrase “may well”—a pretty indecisive headline word—is observed a lot more usually in getting rid of headlines than winning types.
This is intriguing data, but it doesn’t in alone assistance predict whether or not a headline for any presented story will be thriving. Would it be doable to use ML to predict whether a headline would get far more or less clicks? Could we use the accumulated knowledge of Ars viewers to make a black box that could forecast which headlines would be additional effective?
Hell if I know, but we’re likely to check out.
All this provides us to wherever we are now: Ars has offered me knowledge on more than 5,500 headline tests over the earlier 4 years—11,000 headlines, every single with their rate of click-throughs. My mission is to create a device learning model that can compute what tends to make a superior Ars headline. And by “fantastic,” I mean a single that appeals to you, expensive Ars reader. To attain this, I have been given a little funds for Amazon Website Products and services compute methods and a thirty day period of nights and weekends (I have a working day task, following all). No problem, suitable?
Just before I commenced searching Stack Exchange and various Git websites for magical methods, nevertheless, I desired to ground myself in what’s possible with ML and search at what far more talented people than I have presently finished with it. This analysis is as significantly of a roadmap for opportunity remedies as it is a supply of inspiration.